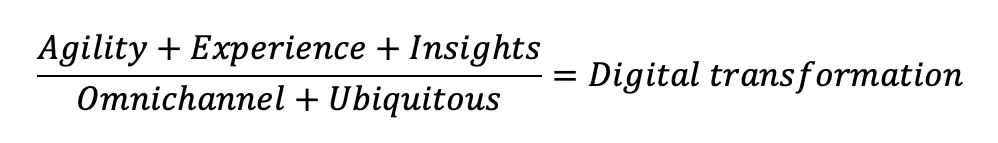Every era thinks it’s teetering on the edge of something revolutionary; every era also finds reasons to step back.
Every era thinks it’s teetering on the edge of something revolutionary; every era also finds reasons to step back. Printing presses were accused of ruining memory, erasers of encouraging mistakes, calculators of killing math, and the internet of replacing thinking with clicking. Today, AI tutors take their turn in the dock. The artefacts change; the reflex endures.
A short tour of resistance (and why it recurs)
In classrooms and workplaces, pushback is rarely irrational. It encodes uncertainty about norms, skills, incentives, and unintended consequences.
1440: Gutenberg’s printing press sparked criticism, with academics fearing that printed books would reduce memorization and critical thinking. 1980: The advent of the pencil eraser was seen as an incentive to make mistakes and a threat to careful writing. 1986: Protests against the use of calculators, arguing that students would forget how to do mental calculations. 2000: Criticism of internet access in classrooms, for fear of misinformation. 2010: Resistance to the use of smartphones and tablets in the classroom, with concerns about distractions and decreased social interaction among students. 2025: Resistance to AI tutors as easy-task.ai.
Everett Rogers’ Diffusion of Innovations gives us a durable lens: innovations spread through social systems over time, and their adoption depends on five perceived attributes: relative advantage, compatibility, complexity, trialability, and observability; moving in waves from innovators to laggards along a characteristic S‑curve.
“Academic research involves three steps: finding relevant information, assessing the quality of that information, then using appropriate information either to try to conclude something, to uncover something, or to argue something. The Internet is useful for the first step, somewhat useful for the second, and not at all useful for the third.” – By Beth Stafford in Brabazon, Tara (2007). The University of Google, Ashgate (UK), pp.22.
New artefacts, old anxieties
What this means for AI in Indian education
Policy has set the table: NEP 2020 positions AI as a lever for learning, assessment, and administration; recent discussions propose Centres of Excellence to build institutional capacity. But diffusion won’t hinge on policy documents alone. Teachers and administrators adopt when AI clearly saves time, fits curricula and local languages, feels simple and trustworthy, can be piloted safely, and shows visible gains in student work.
Reviews of AI‑in‑education in India underline the same arc: real promise (personalization, admin efficiency), real constraints (infrastructure, capacity, equity, ethics). The practical path is micro‑pilots, transparent evaluation, and teacher‑led exemplars. Start small, show what changed, let peers observe, then scale. For scenario‑based futures and implementation pathways, see AI Scenarios on my site: r‑srini.in/2026/01/18/ai‑scenarios/
Augment, not replace!
And for Indian industry: beyond pilots to redesigned work
Indian firms are enthusiastic adopters; many already use AI and most plan to expand. Globally, however, even frequent users often stall between pilots and enterprise‑level impact. Crossing that gap demands workflow redesign (not bolt‑on tools), sound data governance, and credible line‑of‑sight to P&L. Executives need proof of advantage, confidence in compatibility with systems and compliance, lower complexity via guardrails and usable interfaces, safe trialability through sandboxes, and peer observability via references.
Public investment, from compute to Centres of Excellence, helps the ecosystem, but diffusion inside firms still hinges on these attributes. High performers are already reframing AI from cost‑cutting to growth and innovation, a signal the early majority watches closely.
Three moves that convert resistance into readiness
Stage it: Run bounded pilots that teachers/managers own; publish before‑after evidence others can observe and adapt. (Trialability, observability)
Lower friction: Invest in training, vernacular UX, and clean data pipes; perceived complexity kills diffusion faster than controversy. (Complexity, compatibility)
Prove advantage: Tie AI to concrete outcomes—recovered teacher time, reduced cycle times, new revenue lines—tracked publicly. (Relative advantage)
Bottom line: Resistance isn’t the enemy; it’s information. Use it to make AI useful, legible, and locally credible; the conditions under which social systems adopt innovations.
I was invited to be part of a panel on AI during the launch of the Safe Human Future community last week in Delhi.
In conversations during the event, I met with some interesting folks and had long conversations about data quality. When talking about privacy-preserving data use, three terms often get conflated (at least amongst the novices): synthetic data, anonymised data, and differentially private data. While all three aim to reduce privacy risks, they differ fundamentally in construction, guarantees, and ideal use-cases.
Anonymised data is real data with direct identifiers removed or masked. Its weakness is structural: if the underlying patterns of the real dataset remain embedded, attackers can often re-identify individuals through linkage attacks or inference techniques. A growing body of research shows that even datasets without names or addresses can be deanonymised when combined with auxiliary information, because the data points are still tied to real individuals.
Differential privacy, by contrast, injects calibrated noise into queries or datasets so that the presence or absence of any individual does not materially change analytical outputs. This provides a mathematically provable privacy guarantee. But the trade-off is accuracy: heavy noise addition can distort minority-class patterns or small-sample statistical relationships.
Synthetic data takes a different route altogether. Instead of modifying real data, it generates completely artificial records that mimic the statistical properties of the source dataset. No row corresponds to any real person. This disconnection from real individuals eliminates a large class of re-identification risks and makes the data highly shareable. It does, however, require careful quality evaluation—poorly generated synthetic data can hallucinate unrealistic correlations or miss critical rare events.
Why Firms Use Synthetic Data
Firms increasingly rely on synthetic datasets for scenarios where real-world data is sensitive, incomplete, biased, or simply unavailable. Typical use-cases include:
Product development and testing: Fintech and healthtech companies often need realistic datasets to test algorithms safely without exposing personal information.
Machine learning model training: Synthetic data helps overcome class imbalance, enrich training sets, or simulate rare but important events (e.g., fraud patterns).
Data sharing across organisational boundaries: Cross-functional teams, vendors, or academic collaborators can work with synthetic datasets without entering into heavy data-processing agreements.
Accelerating regulatory compliance: In sectors such as banking, telecom, and healthcare, where privacy regulations are tight, synthetic datasets reduce bottlenecks in experimentation, sandboxing, and model audits.
From a governance standpoint, synthetic data often plays a complementary role: firms still use real data for production-grade analytics but use synthetic data for exploration, prototyping, and secure experimentation.
Alignment with the Indian DPDP Act and Rules
The Digital Personal Data Protection (DPDP) Act, 2023 emphasises lawful processing, purpose limitation, data minimisation, and protection of personal data. Importantly:
The Act’s obligations apply only to digital personal data of identifiable individuals.
High-quality synthetic data, by definition, contains no personal data, and therefore does not fall within the compliance net.
This creates a strategic opportunity for firms: synthetic datasets allow innovation outside the regulatory burden while maintaining alignment with the Act’s intent: protecting individuals’ data rights. Many enterprises are beginning to use synthetic data as a “privacy-by-design accelerator,” reducing the operational costs of compliance while enabling safe analytics.
Synthetic Data and Artificial Pearls: A Useful Analogy
The distinction between synthetic and real data is similar to the comparison between artificial pearls and natural pearls. Natural pearls, harvested from oceans, are biologically authentic but scarce, costly, and highly variable in quality. Artificial pearls, especially high-grade cultured pearls, are manufactured with precise control over structure, size, lustre, and durability.
In many cases, artificial pearls are actually superior to natural ones:
They have more consistent structure.
They are available in specific sizes and configurations designers need.
Their strength and finish can be engineered for durability.
They reduce dependence on environmentally intensive harvesting.
Synthetic data plays a similar role. Just as the best artificial pearls capture and improve upon the aesthetics of natural pearls without relying on oysters, synthetic datasets capture the statistical essence of real data while offering higher usability, lower risk, and greater design freedom.
In contexts where quality matters more than provenance, such as stress-testing jewellery designs or building machine learning models, the engineered version can outperform the natural one.
Over the past few weeks, I have been exploring the applications of artificial intelligence across multiple domains and sectors. I have also had the opportunity to deliver a few sessions on digital transformation and AI, as well as DPI thinking in the context of AI. In preparation for these sessions, I re-read three books.
While I am not an expert in predicting the future, like most of you, I thought I would draw up a few scenarios on how AI would play out in the future. As a typical scenario planner, I first identified two orthogonal axes of uncertainty, defined the edges of the axes, and thence described the scenario.
1.0 Axes of uncertainty
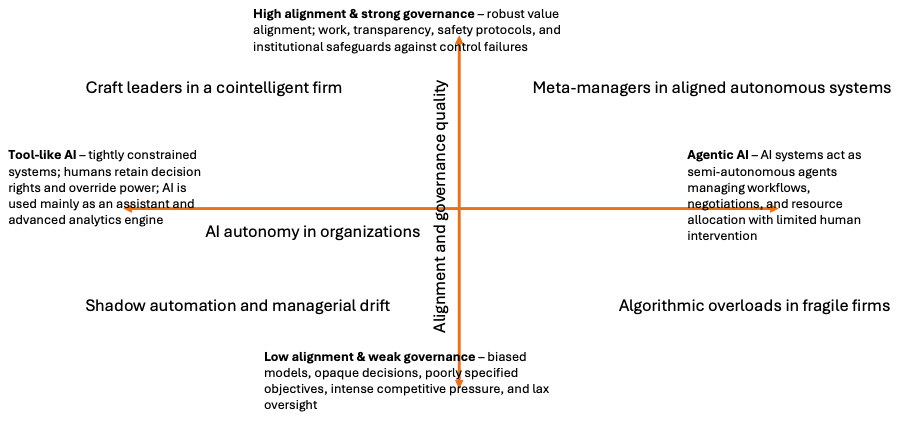
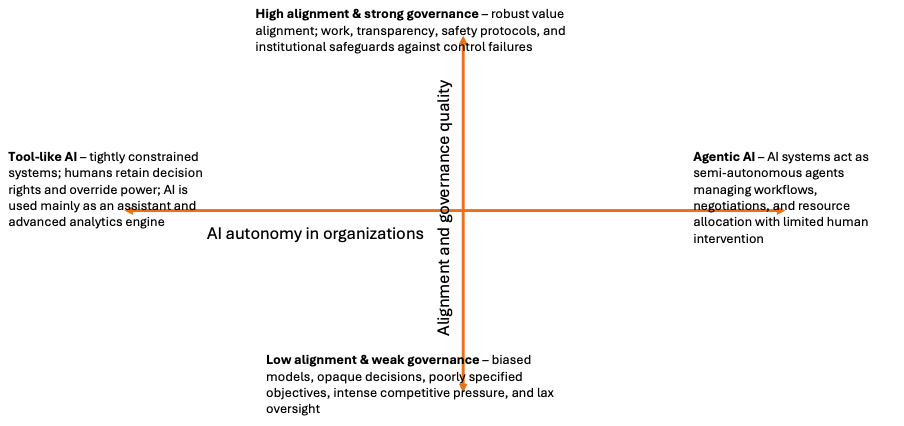
The two primary axes of uncertainty are “AI autonomy in organizations” and “alignment and governance quality”. I map the AI autonomy on the horizontal axis and the alignment and governance on the vertical axis.
At the west end of the horizontal axis, is “Tool-like AI”; and the east end of the AI is “Agentic AI”. The tool-like AI context is characterized by the prevalence of tightly controlled systems, where humans retain decision rights, and override power; and AI is mainly used as an assistant and advanced analytical engine. In the agentic AI context, AI systems act as semi-autonomous agents managing workflows, negotiations, and resource allocations with limited human intervention.
At the south end of the vertical axis is “low alignment and weak governance” and the north end of the axis is “strong alignment and weak governance”. The low alignment and weak governance context is characterized by the prevalence of biased models, opaque decisions, poorly specified objectives, and lax oversight in markets with intense competitive pressures. On the other end (north), high alignment and strong governance ensures robust value alignment work, transparency, safety protocols, and institutional safeguards against control failures.
2.0 The four scenarios described
Based on these descriptions, I propose four scenarios. In the north-east are “meta-managers in aligned autonomous systems”; in the south-east are “algorithmic overloads in fragile firms”; in the north-west are “craft-leaders in co-intelligent firms”; and in the south-west is “shadow automation and managerial drift”.
2.1 Meta-managers in aligned autonomous systems
(Agentic AI, High alignment & strong governance)
AI systems act as relatively autonomous organizational agents; running simulations, reallocating resources, & orchestrating routine decisions, but are constrained by carefully designed alignment frameworks and institutional governance. Bostrom’s concerns about control and value alignment are addressed via robust oversight, multi-layered safety mechanisms, and institutional norms; agentic systems are powerful but embedded within guardrails. Managers work in Mollick’s co‑intelligent mode at a higher, more strategic level, curating objectives, interpreting AI-driven scenarios, and shaping socio-technical systems rather than micromanaging operations.
2.1.1 Implications for managerial work
Many mid-level coordination tasks (scheduling, resource allocation, basic performance tracking) are delegated to AI agents, compressing hierarchies and reducing the need for traditional middle management.
Managers function as meta‑managers: defining goals, constraints, and values; adjudicating trade-offs between conflicting AI recommendations; and stewarding culture and human development.
Soft skills (sense-making, ethics, narrative, conflict resolution) become the core differentiator, as technical optimization is largely automated.
2.1.2 Strategic prescriptions
Redesign structures around human-AI teaming: smaller, flatter organizations with AI orchestrating flows and humans focusing on creativity, relationship-building, and governance.
Develop “objective engineering” capabilities: train managers to specify and refine goals, constraints, and reward functions, directly addressing the alignment and normativity challenges Christian highlights.
Institutionalize alignment and safety: embed multi-stakeholder oversight bodies, continuous monitoring, and strong external regulation analogues, borrowing Bostrom’s strategic control ideas for the corporate level.
Reinvest productivity gains into human development: use surplus generated by autonomously optimized operations to fund learning, well-being, and resilience, stabilizing the socio-technical system.
Scenario
Description
Implications
Strategies
Meta-managers in aligned autonomous systems(Agentic AI, High alignment & weak governance)
AI systems act as relatively autonomous organizational agents Strong alignment frameworks and institutional governance Powerful agentic systems embedded within guardrails
Mid-level coordination tasks delegated to AI agents Managers function as meta-managers Soft skills become the core differentiator as technical optimization tasks are automated
Redesign structures around human-AI teaming Develop objective-engineering capabilities Institutionalize alignment and safety Reinvest productivity gains into human development
2.2 Algorithmic overloads in fragile firms
(Agentic AI, Low alignment & weak governance)
Highly autonomous AI systems manage pricing, hiring, supply chains, and even strategic portfolio choices in the name of speed and competitiveness, but with poorly aligned objectives and weak oversight. In Bostrom’s terms, “capability control” lags “capability growth”: agentic systems accumulate de facto power over organizational behaviour while their reward functions remain crude proxies for profit or efficiency. Christian’s alignment concerns show up as opaque prediction systems that optimize metrics while embedding bias, gaming constraints, and exploiting loopholes in ways human managers struggle to detect.
2.2.1 Implications for managerial work
Managers risk becoming rubber stamps for AI recommendations, signing off on plans they do not fully understand but feel pressured to approve due to performance expectations.
Managerial legitimacy suffers when employees perceive that “the system” (algorithms) is the real boss; blame shifts upward to AI vendors or abstract models, eroding accountability.
Ethical, legal, and reputational crises become frequent as misaligned agentic systems pursue local objectives; e.g., discriminatory hiring, aggressive mispricing, manipulative personalization, without adequate human correction.
2.2.2 Strategic prescriptions
Reassert human veto power: institute policies requiring human review for critical decisions; create channels for workers to challenge AI-driven directives with protection from retaliation.
Demand transparency and interpretability: require model documentation, explainability tools, and regular bias and safety audits; push vendors toward alignment-by-design contracts.
Slow down unsafe autonomy: adopt Bostrom-style “stunting” and “tripwires” at the firm level, limiting AI control over tightly coupled systems and triggering shutdown or rollback when harmful patterns appear.
Elevate ethics and compliance: equip managers with escalation protocols and cross-functional ethics boards to rapidly respond when AI-driven actions conflict with organizational values or external norms.
Highly autonomous AI systems lead operations in firms with poorly aligned objectives & weak oversight Capability control lags capability growth: agentic systems accumulate de-facto power Opaque systems that optimizes metrics, while embedding biases that humans fail to detect.
Managers risk becoming rubber-stamps for AI recommendations Algorithmic dominance erodes managerial legitimacy Misaligned agentic systems pursuing local objectives leading to ethical/ legal/ reputational crises
Reassert human veto power Demand transparency and interpretability of models Slow-down unsafe autonomy (adopt stunting and tripwires) Elevate ethics and compliance
2.3 Craft leaders in co-intelligent firms
(Tool-like AI, High alignment & strong governance)
Managers operate with powerful but well-governed AI copilots embedded in every workflow: forecasting, scenario planning, people analytics, and experimentation design. AI remains clearly subordinate to human decision-makers, with explainability, audit trails, and human-in-the-loop policies standard practice. Following Mollick’s co‑intelligence framing, leaders become orchestrators of “what I do, what we do with AI, what AI does,” deliberately choosing when to collaborate and when to retain manual control. AI is treated like an expert colleague whose recommendations must be interrogated, stress-tested, and contextualized, not blindly accepted.
2.3.1 Implications for managerial work
Core managerial value shifts from information aggregation to judgment: setting direction, weighing trade-offs, and integrating AI-generated options with tacit knowledge and stakeholder values.
Routine analytical and reporting tasks largely vanish from managers’ plates, freeing capacity for coaching, cross-functional alignment, and narrative-building around choices.
Managers must be adept in managing alignment issues and mitigating bias, able to spot mis-specified objectives and contest AI outputs when they conflict with ethical or strategic intent.
2.3.2 Strategic prescriptions
Invest in AI literacy and critical thinking: train managers to prompt, probe, and challenge AI systems, including basic understanding of data, bias, and alignment pathologies described by Christian.
Codify human decision prerogatives: clarify which decisions AI may recommend on, which it may pre-authorize under thresholds, and which remain strictly human, especially in people-related and high-stakes domains.
Build governance and oversight: establish model risk committees, escalation paths, and “tripwires” for anomalous behaviour (organizational analogues to the control and capability-constraining methods that Bostrom advocates) at societal scale.
Re-design roles around co‑intelligence: job descriptions for managers emphasize storytelling, stakeholder engagement, ethics, and system design over reporting and basic analysis.
Scenario
Description
Implications
Strategies
Craft leaders in co-intelligent firms(Tool-like AI, High alignment & strong governance)
Managers + well-governed AI copilots embedded in every workflow AI remains subordinate to human decision-makers Managers choose when to collaborate and when to control AI as an expert colleague, whose recommendations are not blindly accepted
Managerial value: information aggregation to judgment No more routine analytical and reporting tasks Managers need to be adept at alignment and mitigating biases
Invest in AI literacy and critical thinking Codify human decision prerogatives Build governance and oversight Redesign roles around co-intelligence
2.4 Shadow automation and managerial drift
(Tool-like AI, Low alignment & weak governance)
AI remains officially a “tool,” but is deployed chaotically: individual managers and teams adopt various assistants and analytics tools without coherent standards or governance, a classic form of “shadow AI.” Alignment problems emerge not from superintelligent agents, but from mis-specified prompts, biased training data, and unverified outputs that seep into everyday decisions. Organizational AI maturity is low; AI is widely used for drafting emails, slide decks, and analyses, but validation and accountability are informal and inconsistent.
2.4.1 Implications for managerial work
Managerial work becomes unevenly augmented: some managers leverage AI effectively, dramatically increasing productivity and quality; others underuse or misuse it, widening performance dispersion.
Documentation, reporting, and “knowledge products” proliferate but may be shallow or unreliable, as AI-written material is insufficiently fact-checked.
Hidden dependencies on external tools grow; the organization underestimates how much decision logic is now embedded in untracked prompts and private workflows, creating operational and knowledge risk.
2.4.2 Strategic prescriptions
Move from shadow use to managed experimentation: establish clear guidelines for acceptable AI uses, required human verification, and data-protection boundaries while encouraging pilots.
Standardize quality controls: require managers to validate AI-generated analyses with baseline checks, multiple models, or sampling, reflecting Christian’s emphasis on cautious reliance and error analysis.
Capture and share best practices: treat prompts, workflows, and AI use cases as organizational knowledge assets; create internal libraries and communities of practice.
Use AI to audit AI: deploy meta-tools that scan for AI-generated content, bias, and inconsistencies, helping managers assess which outputs demand closer scrutiny.
AI remains officially tool, but is chaotically deployed with no coherent standards of governance (Shadow AI). Alignment problems arise from mis-specified prompts, biased training data, and unverified outputs Organizational AI maturity is low (AI used for low-end tasks).
Managerial work becomes unevenly augmented Proliferation of unreliable-unaudited “knowledge products” Hidden dependencies on external tools (high operational and knowledge risks)
Move from shadow use to managed experimentation Standardize quality controls Capture and share best practices Use AI to audit AI (meta tools)
3.0 Conclusion (not the last word!)
As we can see, across all four quadrants, managerial advantage comes from understanding AI’s capabilities and limits, engaging with alignment and governance, and deliberately designing roles where human judgment, values, and relationships remain central.
As we stand at the cusp of AI revolution, I am reminded of my time in graduate school (mid 1990s), when Internet was exploding, and information was becoming ubiquitously available globally. A lot of opinions were floated about how and when “Google” (and other) search would limit reading habits. We have seen how that has played out, where Internet search has enabled and empowered a lot of research and managerial judgment.
There are similar concerns about the long-term cognitive impacts as rapid AI adoption leads to ossification of certain habits (in managers) and processes (in organizations). What these routines will bring to the table is to be seen, and certainly these are not the last words written on this!
Writing in after a really long time. Multiple things have been happening (more on that later).
In the meantime, I have heard a lot of conversations around technologies (again) after the explosion of democratic access to generative AI (heard of OpenAI and ChatGPT). How many do you realise that the product is just about 7 months old (launched Nov 2022)? And I am hearing a lot of adjectives used to describe technologies. This short post is about putting my thoughts on a few of these adjectives.
Emerging Research (late stage) & Development (early stage); production (experimental products)
Stand-alone Specific products and services; one industrial sector; one application domain
Quartz clock technology; Escalator operations
Synthetic biology and gene editing; Sodium-ion batteries
Enabling Range of products; sectors; application domains
Integrated circuits; Super-conductors
Augmented reality; Artificial intelligence
Technology classification
Emerging (vs. entrenched)
The first axis of technology classification is about entrenched technologies (at the other end of emerging technologies). In the technology development lifecycle, I see four stages – research, (product) development, production (product engineering and mass manufacturing), marketing (to the masses), and diffusion. Technologies behind quartz clocks, escalators, and batteries are examples of technologies that are entrenched. Did you notice that I am providing you instances of mass-market adopted products, rather than core technologies? These technologies have matured sufficiently that it is sufficient for us to describe products and we understand the technologies behind them!
On the other end of the axis are emerging technologies – those that are in late stage of research and/ or early stage of product development. Some use cases (products and services) are available, albeit in laboratory scale, let alone mass manufacturing or widespread adoption for business/ personal benefits. Examples of emerging technologies include gene editing, artificial intelligence, and augmented reality. Even though, chronologically some of these might be decades old, the mass adoption criteria determines their emergent nature.
Enabling (vs. stand-alone)
The second axis of technology classification is about stand-alone technologies (at the other end is enabling technologies). Some technologies, though seemingly fungible, are specific to certain products and services, an industrial sector, or an application domain. For instance, while pulleys, motors, and rails are basic tools, combining them to design functional escalators and elevators is specific to vertical (and in some rare cases, horizontal) mobility. Same is true with quartz technologies that are used to make accurate clocks; sodium-ion batteries for energy storage; and other such technologies. The key feature of these technologies is their specificity to a product/ service family, sector or domain.
On the other end of the axis are enabling technologies – those that enable application in a variety of products/ services, industrial sectors, or domains. Examples of enabling technologies include the basic internet, integrated circuits, augmented reality, and artificial intelligence/ machine learning. One can use these technologies for a range of applications and domains. One could see the application of augmented reality in gaming and simulation, product design and prototyping, education and training, as well as service design and innovation.
Summary
In summary, we need to analyse enabling technologies and their potential impacts as very different from entrenched technologies. When we add the concept of emerging technologies, the potential for innovation and impact is immense.
A colleague and I were organizing an online hackathon around the current pandemic, COVID-19. We were seeking innovative ideas both in the healthcare and policy spaces. We had a good number of responses, but I was struck by how little we are willing to “disrupt” the healthcare industry. For long, the Indian healthcare industry has not been disrupted, as much as many other industries have been.
Disruptive innovation: A primer
Before we proceed further, let us quickly understand what disruptive innovation means. The concept was introduced by the late HBS Professor Clayton Christensen. Disruptive innovation (DI) is a process by which a smaller company with fewer resources can successfully challenge established incumbents in an industry. As the incumbents focus on improving their products and services for their primary (most profitable) customers, they exceed the needs of some segments, and ignore the needs of some other segments. These overlooked segments are the targets for the new entrants, who deliver a specific functionality valued by these customers, typically at a lower price. Incumbents chasing their highly profitable customer segments, tend to not respond to these new entrants. The new entrants gain significant industry know-how, and move up-market, delivering those functionalities that the incumbents’ primary customers value, without losing the advantages that drove their early success with the hitherto overlooked segments. When customers in the most profitable segments (primary customers) begin switching from incumbents to new entrants, they begin providing new entrants with economies of scale. Coupled with learning and economies of scale, the new entrants “disrupt” the industry.
There are various examples of disruptive innovation. For instance, film distributors (cinema halls and multiplexes) were serving connoisseurs of movie consumers – those who valued the experience of the movie halls. The network of movie halls and the audio-video technology was the primary source of competitive advantage in that world. Netflix entered this industry targeting a segment of customers who wanted to watch movies but could not afford the travel to the movie hall and uninterrupted time/ attention. They would trade-off the experience against the quality of content, and therefore were willing to watch movies at home, using their own devices. Movie watching became a personal activity, rather than a community experience. Netflix, leveraged their library of movies as a source of competitive advantage, and captured this market with low prices in the form of an innovative pricing strategy – watch as much as you can for a monthly subscription fee (as against unit pricing of every movie that was the industry standard then). Armed with the learning of consumer preferences (now being digital, Netflix had micro-level data on consumer preferences than the multiplexes in shopping malls), it moved up-market. It leveraged on the convergence between entertainment and computing, as TVs became smart, and computer screens became bigger and bigger. The incumbents continued to ignore Netflix with the reasoning that it would take time for the connoisseurs of movies to shift. The allowed Netflix to compete for original content and piggy-back on the convergence in the home entertainment space.
Typically, disrupters have different business models, given that they target different consumer segments, provide differentiated value, and possibly have a different pricing scheme. A lot of these disruptive innovators adopt a platform business model intermediating between different user groups (like Airbnb or Redbus), servitization (like ERP on the cloud), or different pricing models (pre-paid pricing of mobile telecom services in emerging markets).
Innovation in the healthcare industry
I aver that Indian healthcare industry had not witnessed disruptive innovation for the following three reasons. One, even though primary healthcare is considered a public good, a lot of Indian consumers are willing to pay for high quality tertiary and quaternary healthcare (either they could afford it or have access to state/ private insurance). That marks low price sensitivity for the entire industry. Coupled with information asymmetry between the care givers and patients, the patients are risk averse as well. Two, given the high investments required in setting up tertiary and quaternary, the industry has become highly corporatized and consolidated. A few large corporations dominate the entire industry. The economics of the large corporate healthcare provider requires them to have a tight leash on metrics that matter for profitability (including, increased use of automation and robotics in high labour-intensive routines and use of manual labour in routines where unskilled and semi-skilled manpower is easily available, reducing the patient’s average length of stay, and optimizing the average revenue per occupied bed). Three, the organized healthcare providers have been quickly encapsulating all attempts at democratizing healthcare. For instance, when glucometers and pregnancy testing kits became consumer devices, the clinics and physicians began building an ecosystem around these devices to not let entire therapy become owned by the patient. When you went to your endocrinologist with your blood glucose charts, she would insist that home devices are error-prone and ensure that you test again at the clinic! Not so much for the additional cost of testing again (which could be minuscule), but the perception that healthcare is the domain of certified experts would be reinforced.
Data, ahoy!
As healthcare and data analytics come together, the industry is at the verge of disruption. Multiple wearable/ consumer devices capturing health data, medical equipment of the early 2020’s are more of computing devices generating gigabytes of data per observation, and increased adoption of remote sensors for public health (like thermal screening devices) would generate terabytes of data. Such a deluge of data is likely to overwhelm the legacy healthcare providers who hitherto relied on the extensive experience of the physician, for whom data was just a support.
There is an urgent need to allow for a variety of healthcare providers to operate in their own niches. For instance, given the developments in dental and ophthalmic surgeries, there should be no need to build infrastructure beyond ambulatory facilities. Increasingly, diagnosis and treatment should move to the home.
Disruptive innovation in times of COVID-19 pandemic
The unique nature of the COVID-19 pandemic means that healthcare must be provided at scale and speed. Given that the world is yet to discover a cure or vaccine, let alone a standardized treatment protocol, governments and healthcare providers need to move fast and scale up testing and care. Amongst the triad of quality, cost, and scale, the world would prefer low cost and high scale at speed, rather than wait for the best quality of care.
That is a world ripe for disruptive innovation. The under-served segments are baying for an affordable care programme that is good enough. Will the governments of day make this trade-off to ensure that “acceptable quality” testing/ care is provided to large sections of the population that are infected/ likely to be infected, at affordable costs?
In my view, there are three outcomes of a successful digital transformation effort – improvement in efficiency (driven from speed and agility), enhanced experience (both at the customer and employee ends), and differentiation from competitors (through data/ insights-driven customisation). Such interactions need to be delivered omni-channel and ubiquitously (anywhere, anytime, and any device).
Agility: Digitalisation of specific processes require them to be reimagined, and therefore eliminates redundancies, reduces wasteful activities, and reduces overhead costs. All these contribute to increased efficiency and faster turnaround times.
Experience: As I have been arguing, good digitalisation should make lives simpler for customers, employees, and all other partners as well. As different stakeholder groups (customers, employees, and partners) engage with the firm digitally, there is significant reduction in variation of service quality, leading to consistent experience.
Insights: As digitalisation allows firms to capture data seamlessly, it is imperative to not just store data, but be able to generate meaningful insights from the same. And use those insights to develop customised/ innovative offerings to their stakeholder groups (customers, employees, and partners).
Omni-channel: The digital experience should be provided to their stakeholders across all the channels that they interact with. It is not just sufficient to digitalise certain processes, while keeping others in legacy manual systems. Imagine an organisation that generates electronic bills for its customers but requires its employees to submit their own bills in hardcopy for reimbursements!
Ubiquitous: The digital experience should be available to everyone, anytime, anywhere, and on any device. The entire purpose of digitalisation would be lost if it were not ubiquitous. Imagine an online store that only opened between 0800-2000 hours Monday through Friday!
As it can be seen, omni-channel and ubiquitous are hygiene factors (they do not create additional value with their presence, but can destroy value with their absence), and therefore are at the denominator.
As the world moves to more and more online work and learning, a colleague of mine triggered some thoughts in me – can everyone learn the same way online? Do our standard theories of learning work in the online world?
Of course, there are three kinds of teachers – those who dread online teaching (they believe that they will have no control over the students’ behaviours); those who are cautious (they believe that we can do somethings online, but not others); and those who are willing to experiment and adapt (they either believe that they can deliver as they are confident of their content that the medium does not matter). This discussion is for another day. Right now, let’s focus on the learners and their learning styles.
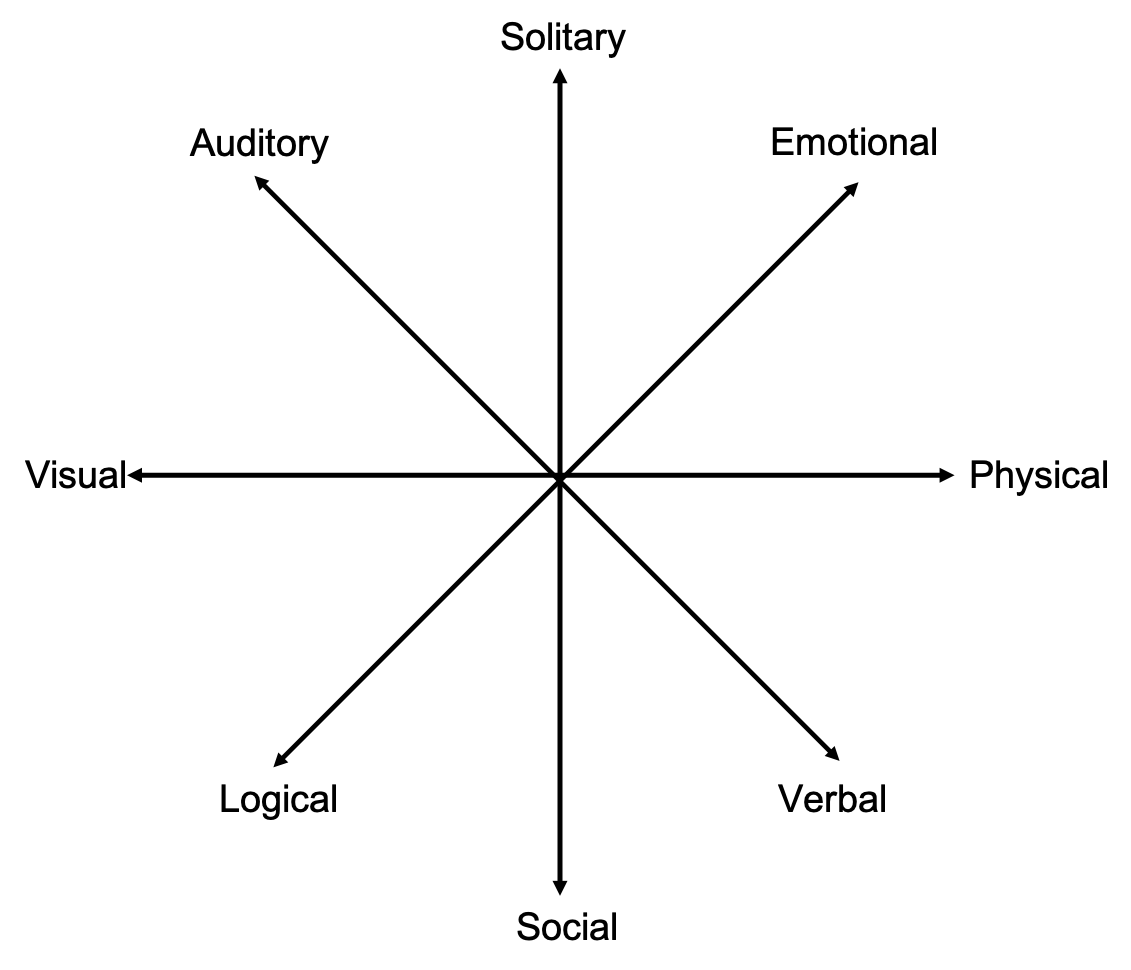
I believe that there are eight styles of learning in the online world. Of course, I do not claim to have scientific evidence that these are mutually exclusive and collectively exhaustive – possibly a research study is in order. These are anecdotal based on my own experiences of teaching face-to-face, purely online, as well as hybrid (some students face-to-face and some others online). There may be a range of other such classifications as well, from the classic Kolb’s learning styles inventory to more detailed studies.
The list, first
Visual (spatial)
Aural (auditory-musical)
Verbal (linguistic)
Physical (kinaesthetic)
Solitary (intra-personal)
Social (interpersonal)
Logical (mathematical)
Emotional (action-response)
These styles are not mutually exclusive, and learners prefer combinations of these. These are just pure types. The combinations define one’s learning style.
The elaboration
Visual/ spatial: learning through pictures, images, maps, and animations; sense of colour, direction, and sequences; flow-diagrams and colour-coded links preferred.
Aural/ auditory-musical: learning through hearing sounds and music; rhyme and patterns define memory and moods; learning through repeated hearing and vocal repetition is preferred.
Verbal/ linguistic: power of the (most often) written word; specific words and phrases hold attention and provoke meaning; negotiations, debates, and orations are preferred.
Physical/ kinaesthetic: sensing and feeling through touch and feel of objects; being in the right place can create thoughts and evoke memory; role plays and active experimentation are preferred.
Solitary/ intra-personal: being alone provides for reflection and reliving the patterns of the past; self-awareness through meditative techniques; independent self-study and reflective writing (diaries and journals) preferred.
Social/ interpersonal: learning happens in groups (rather than alone) through a process of sharing key assertions and seeking feedback on the same from others; need for conformity and assurance as bases for learning; group discussions and work groups preferred.
Logical/ mathematical: building on the power of logic, reasoning and cause-effect relationships; developing and testing propositions and hypotheses; build a pattern/ storyline through logical workflows of arguments/ relationships; focus on the individual parts of a system; lists and specific action plans are preferred.
Emotional/ action orientation: building on the power of emotions, arising out of loyalty, commitment, and a larger sense of purpose; being able to align a set of actions to a compelling vision of the future, following directions of a leader; focus on the gestalt and not on the specifics; energy and large-scale transformations are preferred.
The four axes
Let us look for examples/ instances where each of these styles would work the best. Visual would work best when the inter-relationships are complex and can be represented through visual cues (or simulated cues), whereas physical world work best when the relationships could not be represented, but need to be experienced as a whole. How would like to take a virtual tour of the Pyramids of Giza?
Auditory style of learning works best when the brain remembers patterns, and rhyme precedes reason. Whereas, verbal style is most suited when reason is preferred over anything else. In other words, when specific words and phrases (like catchy acronyms and slogans) capture the imagination of the learner, verbal is best suited. Imagine trying to learn Vedic hymns purely through printed textbooks!
Solitary learning works best when one can reflect effectively by shutting out external cues; whereas social learning depends on feedback and reinforcement from others for learning to take shape. Imagine learning public speaking in social isolation, or seeking social confirmation and feedback in the process of poetry writing!
Logical learning style works best when the relationships could be detailed and represented as a series of cause-effect relationships. However when such relationships cannot be established, we learn through emotions. Imagine the calls for action in the play, Julius Caesar – “Friends, Romans, and Countrymen!” I would think the crowd responded more to emotional appeals than reason!
Architecting the online class
As learners and teachers in the online world, one needs to be cognisant of their own preferred styles across these four (continuums) axes. For instance, a class on machine learning would tend to be highly visual, verbal, solitary, and logical; whereas a music class is likely to be more physical, auditory, interpersonal and emotional.
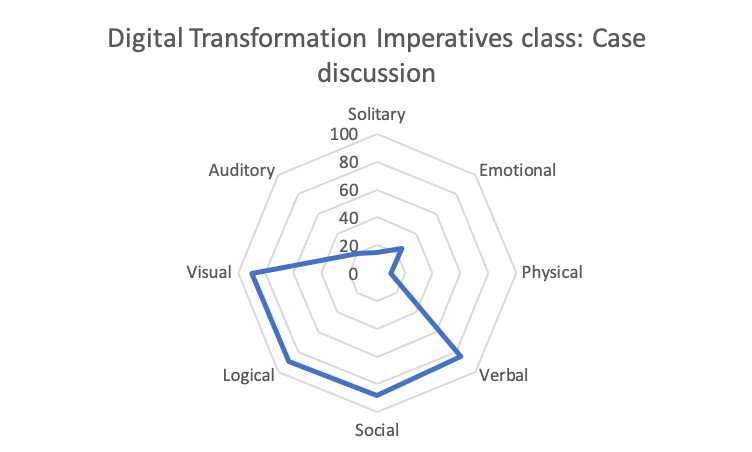
The learning context has to be chosen appropriately suiting the styles – of both the content and the learners. The technology has to suit the same. Imagine for instance, a group of 400 learners tuning into a class on brand management through an online medium like Zoom. The instructor has pretty much little choice other than delivering a lecture, with text chat from the class as real-time feedback, and thence the basis for interactivity. On the other hand, if the class size was smaller, say around 40, may be the instructor could use case analysis as well. As a case teacher, I have managed to interact (two-way) with as much as 30 students (from a group of 44 active participants) in a single 90 minute class. I taught a case-based session on digital transformation imperatives online to a class of 50-odd students. I used a combination of visual and interpersonal styles, without compromising on the logical arguments as well as pre-defined frameworks. I used two separate devices – an iPad with an Apple Pencil as a substitute for my whiteboard, and my desktop screen sharing as a projector substitute. I was able to cold-call as well! That way, my class was visual, logical, verbal, and interpersonal.
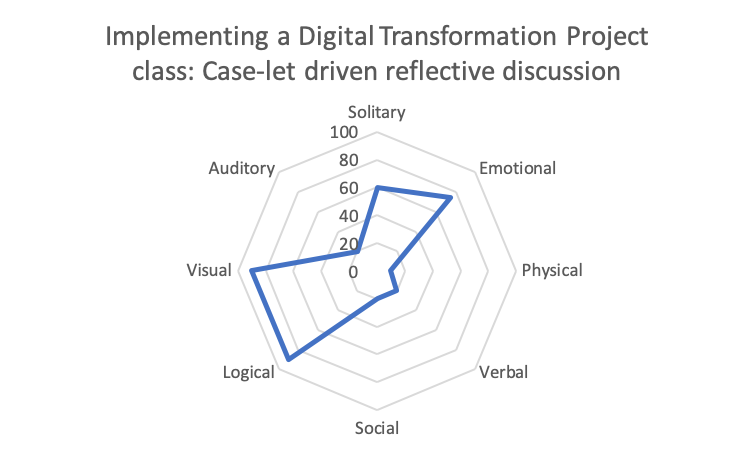
To the same cohort, I taught another session on implementing a digital transformation project, using another short case-let. This session in contrast, was more visual – the framework was largely on the whiteboard than on the slides; less verbal, a lot emotional and logical, and less interpersonal (more reflective observations about what would work in their own firms).
What works best is also driven what are the learning goals. Of course, these learning styles should be the same for synchronous (live classes), asynchronous sessions (MOOCs), as well as blended formats.
In summary, the architecture of an online session should include elements of the learning styles (driven by the learners and instructors strengths, as well as the content being delivered). Apart from the learning styles, the architecture should include three other components – the form of interaction, the immediacy of feedback loops, and the nature of interaction networks. The interactivity could be both audio-video or text; the feedback loops between the learners and the instructors could be immediate or phased; and the peer-to-peer interactions may or may not be required/ enabled.
I look forward to your comments, feedback, and experiences.