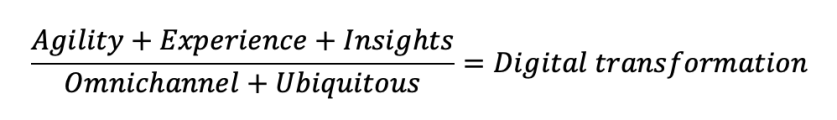A colleague and I were organizing an online hackathon around the current pandemic, COVID-19. We were seeking innovative ideas both in the healthcare and policy spaces. We had a good number of responses, but I was struck by how little we are willing to “disrupt” the healthcare industry. For long, the Indian healthcare industry has not been disrupted, as much as many other industries have been.
Disruptive innovation: A primer
Before we proceed further, let us quickly understand what disruptive innovation means. The concept was introduced by the late HBS Professor Clayton Christensen. Disruptive innovation (DI) is a process by which a smaller company with fewer resources can successfully challenge established incumbents in an industry. As the incumbents focus on improving their products and services for their primary (most profitable) customers, they exceed the needs of some segments, and ignore the needs of some other segments. These overlooked segments are the targets for the new entrants, who deliver a specific functionality valued by these customers, typically at a lower price. Incumbents chasing their highly profitable customer segments, tend to not respond to these new entrants. The new entrants gain significant industry know-how, and move up-market, delivering those functionalities that the incumbents’ primary customers value, without losing the advantages that drove their early success with the hitherto overlooked segments. When customers in the most profitable segments (primary customers) begin switching from incumbents to new entrants, they begin providing new entrants with economies of scale. Coupled with learning and economies of scale, the new entrants “disrupt” the industry.
There are various examples of disruptive innovation. For instance, film distributors (cinema halls and multiplexes) were serving connoisseurs of movie consumers – those who valued the experience of the movie halls. The network of movie halls and the audio-video technology was the primary source of competitive advantage in that world. Netflix entered this industry targeting a segment of customers who wanted to watch movies but could not afford the travel to the movie hall and uninterrupted time/ attention. They would trade-off the experience against the quality of content, and therefore were willing to watch movies at home, using their own devices. Movie watching became a personal activity, rather than a community experience. Netflix, leveraged their library of movies as a source of competitive advantage, and captured this market with low prices in the form of an innovative pricing strategy – watch as much as you can for a monthly subscription fee (as against unit pricing of every movie that was the industry standard then). Armed with the learning of consumer preferences (now being digital, Netflix had micro-level data on consumer preferences than the multiplexes in shopping malls), it moved up-market. It leveraged on the convergence between entertainment and computing, as TVs became smart, and computer screens became bigger and bigger. The incumbents continued to ignore Netflix with the reasoning that it would take time for the connoisseurs of movies to shift. The allowed Netflix to compete for original content and piggy-back on the convergence in the home entertainment space.
Typically, disrupters have different business models, given that they target different consumer segments, provide differentiated value, and possibly have a different pricing scheme. A lot of these disruptive innovators adopt a platform business model intermediating between different user groups (like Airbnb or Redbus), servitization (like ERP on the cloud), or different pricing models (pre-paid pricing of mobile telecom services in emerging markets).
Innovation in the healthcare industry
I aver that Indian healthcare industry had not witnessed disruptive innovation for the following three reasons. One, even though primary healthcare is considered a public good, a lot of Indian consumers are willing to pay for high quality tertiary and quaternary healthcare (either they could afford it or have access to state/ private insurance). That marks low price sensitivity for the entire industry. Coupled with information asymmetry between the care givers and patients, the patients are risk averse as well. Two, given the high investments required in setting up tertiary and quaternary, the industry has become highly corporatized and consolidated. A few large corporations dominate the entire industry. The economics of the large corporate healthcare provider requires them to have a tight leash on metrics that matter for profitability (including, increased use of automation and robotics in high labour-intensive routines and use of manual labour in routines where unskilled and semi-skilled manpower is easily available, reducing the patient’s average length of stay, and optimizing the average revenue per occupied bed). Three, the organized healthcare providers have been quickly encapsulating all attempts at democratizing healthcare. For instance, when glucometers and pregnancy testing kits became consumer devices, the clinics and physicians began building an ecosystem around these devices to not let entire therapy become owned by the patient. When you went to your endocrinologist with your blood glucose charts, she would insist that home devices are error-prone and ensure that you test again at the clinic! Not so much for the additional cost of testing again (which could be minuscule), but the perception that healthcare is the domain of certified experts would be reinforced.
Data, ahoy!
As healthcare and data analytics come together, the industry is at the verge of disruption. Multiple wearable/ consumer devices capturing health data, medical equipment of the early 2020’s are more of computing devices generating gigabytes of data per observation, and increased adoption of remote sensors for public health (like thermal screening devices) would generate terabytes of data. Such a deluge of data is likely to overwhelm the legacy healthcare providers who hitherto relied on the extensive experience of the physician, for whom data was just a support.
There is an urgent need to allow for a variety of healthcare providers to operate in their own niches. For instance, given the developments in dental and ophthalmic surgeries, there should be no need to build infrastructure beyond ambulatory facilities. Increasingly, diagnosis and treatment should move to the home.
Disruptive innovation in times of COVID-19 pandemic
The unique nature of the COVID-19 pandemic means that healthcare must be provided at scale and speed. Given that the world is yet to discover a cure or vaccine, let alone a standardized treatment protocol, governments and healthcare providers need to move fast and scale up testing and care. Amongst the triad of quality, cost, and scale, the world would prefer low cost and high scale at speed, rather than wait for the best quality of care.

That is a world ripe for disruptive innovation. The under-served segments are baying for an affordable care programme that is good enough. Will the governments of day make this trade-off to ensure that “acceptable quality” testing/ care is provided to large sections of the population that are infected/ likely to be infected, at affordable costs?
Stay healthy, stay hydrated, stay safe!
Cheers.
(c) 2020. Srinivasan R